

Is Naive Bayes Supervised Learning
Note: This commodity was originally published on Sep 13th, 2015 and updated on Sept 11th, 2017
Overview
- Understand one of the most pop and simple motorcar learning classification algorithms, the Naive Bayes algorithm
- It is based on the Bayes Theorem for computing probabilities and conditional probabilities
- Learn how to implement the Naive Bayes Classifier in R and Python
Introduction
Here's a situation you've got into in your data scientific discipline project:
Yous are working on a nomenclature problem and have generated your set of hypothesis, created features and discussed the importance of variables. Within an hr, stakeholders desire to see the showtime cut of the model.
What will you do? You have hundreds of thousands of data points and quite a few variables in your training data gear up. In such a situation, if I were in your place, I would have used 'Naive Bayes', which can be extremely fast relative to other classification algorithms. It works on Bayes theorem of probability to predict the class of unknown data sets.
In this article, I'll explicate the basics of this algorithm, so that next time when you come across large data sets, you lot tin bring this algorithm to action. In addition, if you are a newbie in Python or R, you should not be overwhelmed by the presence of available codes in this article.
If you prefer to learn Naive Bayes theorem from the nuts concepts to the implementation in a structured manner, you can enroll in this complimentary course:
- Naive Bayes from Scratch
Are y'all a beginner in Auto Learning? Do you want to master the machine learning algorithms like Naive Bayes? Here is a comprehensive class covering the motorcar learning and deep learning algorithms in particular –
- Certified AI & ML Blackbelt+ Program
Project to apply Naive Bayes
Problem Statement
HR analytics is revolutionizing the mode human resources departments operate, leading to higher efficiency and ameliorate results overall. Human resources have been using analytics for years.
Yet, the collection, processing, and assay of data have been largely manual, and given the nature of human resource dynamics and HR KPIs, the arroyo has been constraining Hr. Therefore, it is surprising that Hr departments woke upwardly to the utility of machine learning then late in the game. Here is an opportunity to endeavor predictive analytics in identifying the employees most probable to get promoted.
Practice At present
Table of Contents
- What is Naive Bayes algorithm?
- How Naive Bayes Algorithms works?
- What are the Pros and Cons of using Naive Bayes?
- 4 Applications of Naive Bayes Algorithm
- Steps to build a basic Naive Bayes Model in Python
- Tips to improve the ability of Naive Bayes Model
What is Naive Bayes algorithm?
It is a classification technique based on Bayes' Theorem with an assumption of independence among predictors. In elementary terms, a Naive Bayes classifier assumes that the presence of a particular characteristic in a form is unrelated to the presence of any other feature.
For case, a fruit may be considered to be an apple if it is carmine, round, and almost 3 inches in diameter. Fifty-fifty if these features depend on each other or upon the existence of the other features, all of these backdrop independently contribute to the probability that this fruit is an apple tree and that is why it is known as 'Naive'.
Naive Bayes model is easy to build and peculiarly useful for very large data sets. Forth with simplicity, Naive Bayes is known to outperform even highly sophisticated classification methods.
Bayes theorem provides a way of calculating posterior probability P(c|x) from P(c), P(10) and P(x|c). Wait at the equation below:
 Higher up,
Higher up,
- P(c|10) is the posterior probability of class (c,target) given predictor (ten,attributes).
- P(c) is the prior probability of class.
- P(x|c) is the likelihood which is the probability of predictor given course.
- P(x) is the prior probability of predictor.
How Naive Bayes algorithm works?
Let'south sympathize it using an example. Below I have a training data set of atmospheric condition and corresponding target variable 'Play' (suggesting possibilities of playing). Now, we need to classify whether players volition play or not based on atmospheric condition. Let'due south follow the below steps to perform it.
Pace 1: Convert the information ready into a frequency table
Step 2: Create Likelihood table past finding the probabilities similar Overcast probability = 0.29 and probability of playing is 0.64.
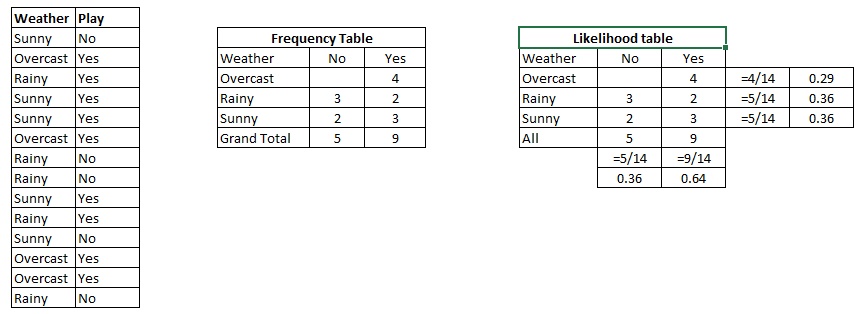
Pace 3: Now, use Naive Bayesian equation to summate the posterior probability for each class. The class with the highest posterior probability is the outcome of prediction.
Problem: Players will play if weather is sunny. Is this statement is correct?
We tin can solve information technology using above discussed method of posterior probability.
P(Yes | Sunny) = P( Sunny | Yes) * P(Yeah) / P (Sunny)
Here we accept P (Sunny |Yes) = 3/9 = 0.33, P(Sunny) = 5/14 = 0.36, P( Yes)= 9/14 = 0.64
Now, P (Yes | Sunny) = 0.33 * 0.64 / 0.36 = 0.60, which has college probability.
Naive Bayes uses a similar method to predict the probability of different grade based on diverse attributes. This algorithm is more often than not used in text nomenclature and with problems having multiple classes.
What are the Pros and Cons of Naive Bayes?
Pros:
- It is piece of cake and fast to predict class of test information set. It likewise perform well in multi class prediction
- When assumption of independence holds, a Naive Bayes classifier performs better compare to other models like logistic regression and you lot need less grooming information.
- It perform well in case of categorical input variables compared to numerical variable(s). For numerical variable, normal distribution is assumed (bell curve, which is a stiff assumption).
Cons:
- If categorical variable has a category (in test information gear up), which was not observed in training data set, then model will assign a 0 (zero) probability and will be unable to make a prediction. This is often known as "Nix Frequency". To solve this, we tin can utilise the smoothing technique. One of the simplest smoothing techniques is called Laplace estimation.
- On the other side naive Bayes is also known as a bad estimator, and then the probability outputs from predict_proba are not to exist taken also seriously.
- Another limitation of Naive Bayes is the supposition of independent predictors. In existent life, it is almost impossible that we get a fix of predictors which are completely independent.
four Applications of Naive Bayes Algorithms
- Real time Prediction:Naive Bayes is an eager learning classifier and it is sure fast. Thus, information technology could be used for making predictions in real time.
- Multi class Prediction:This algorithm is likewise well known for multi class prediction characteristic. Here we can predict the probability of multiple classes of target variable.
- Text nomenclature/ Spam Filtering/ Sentiment Analysis: Naive Bayes classifiers mostly used in text classification (due to better upshot in multi class problems and independence rule) accept higher success charge per unit as compared to other algorithms. As a result, it is widely used in Spam filtering (identify spam e-mail) and Sentiment Analysis (in social media analysis, to place positive and negative customer sentiments)
- Recommendation Organisation:Naive Bayes Classifier and Collaborative Filtering together builds a Recommendation Organization that uses machine learning and data mining techniques to filter unseen information and predict whether a user would like a given resources or not
How to build a basic model using Naive Bayes in Python and R?
Again, scikit larn (python library) volition help here to build a Naive Bayes model in Python. In that location are three types of Naive Bayes model nether the scikit-learn library:
-
Gaussian:It is used in nomenclature and it assumes that features follow a normal distribution.
-
Multinomial:Information technology is used for discrete counts. For example, let's say, we have a text nomenclature problem. Here we can consider Bernoulli trials which is one step further and instead of "word occurring in the document", we have "count how frequently word occurs in the document", you tin can think of it equally "number of times upshot number x_i is observed over the n trials".
-
Bernoulli:The binomial model is useful if your characteristic vectors are binary (i.e. zeros and ones). I application would be text classification with 'bag of words' model where the 1s & 0s are "discussion occurs in the certificate" and "discussion does not occur in the document" respectively.
Python Code:
Try out the beneath code in the coding window and cheque your results on the fly!
R Code:
require(e1071) #Holds the Naive Bayes Classifier Train <- read.csv(file.choose()) Test <- read.csv(file.cull()) #Make sure the target variable is of a two-grade classification trouble only levels(Train$Item_Fat_Content) model <- naiveBayes(Item_Fat_Content~., information = Train) class(model) pred <- predict(model,Test) table(pred)
Higher up, we looked at the basic Naive Bayes model, you can better the power of this basic model by tuning parameters and handle assumption intelligently. Let'south look at the methods to improve the performance of Naive Bayes Model. I'd recommend you lot to get through this certificate for more than details on Text classification using Naive Bayes.
Tips to improve the ability of Naive Bayes Model
Hither are some tips for improving power of Naive Bayes Model:
- If continuous features do not have normal distribution, we should use transformation or dissimilar methods to catechumen it in normal distribution.
- If exam data ready has zilch frequency issue, apply smoothing techniques "Laplace Correction" to predict the class of exam data set.
- Remove correlated features, as the highly correlated features are voted twice in the model and it tin lead to over inflating importance.
- Naive Bayes classifiers has limited options for parameter tuning similar alpha=1 for smoothing, fit_prior=[True|False] to learn grade prior probabilities or not and another options (look at detail here). I would recommend to focus on your pre-processing of data and the characteristic choice.
- You might think to apply some classifier combination technique likeensembling, bagging and boosting but these methods would not assist. Actually, "ensembling, boosting, bagging" won't assistance since their purpose is to reduce variance. Naive Bayes has no variance to minimize.
End Notes
In this article, we looked at one of the supervised machine learning algorithm "Naive Bayes" mainly used for classification. Congrats, if y'all've thoroughly & understood this article, y'all've already taken you offset step to chief this algorithm. From here, all you lot demand is practice.
Further, I would advise yous to focus more on data pre-processing and characteristic option prior to applying Naive Bayes algorithm.0 In future post, I will discuss virtually text and document classification using naive bayes in more item.
Did you lot find this article helpful? Please share your opinions / thoughts in the comments department below.
You can use the following gratuitous resource to larn- Naive Bayes-
- Automobile Learning Certification Course for Beginners
Acquire, engage, compete, and get hired!

Is Naive Bayes Supervised Learning,
Source: https://www.analyticsvidhya.com/blog/2017/09/naive-bayes-explained/
Posted by: garrettnectur.blogspot.com
0 Response to "Is Naive Bayes Supervised Learning"
Post a Comment